大数据与艺术
陈一昕 / 2014-09-13
本文为陈一昕在中关村大数据产业联盟“大数据100分”论坛上的交流探讨实录
主讲嘉宾:陈一昕
主持人:中关村大数据产业联盟副秘书长陈新河
承办:中关村大数据产业联盟
嘉宾介绍:
陈一昕:博士,中国科技大学少年班本科毕业,美国伊利诺大学香槟分校获计算机科学博士学位.美国华盛顿大学计算机系副教授,终身教授,博士生导师,中国 科学院计算所客座研究员,中国科技大学计算机系客座教授,中国联通研究院大数据首席专家,中国科技部973项目负责人。研究领域为数据挖掘,机器学习,优 化算法,医疗大数据,人工智能,云计算等。在TKDE,TKDD,JAIR,AIJ等国际一流期刊和ICML,KDD,IJCAI,AAAI等顶级会议和 上发表论文100余篇。任大数据领域多个顶级学术期刊编委和多个一流国际会议的程序委员会委员。为美国国家科学基金委,香港研究基金委,奥地利国家科学基 金委,瑞士国家科学基金委,中国科技部科技评估中心的评审委员。中国科技大学所承担的教育部111引智计划专家组专家成员之一,中国计算机学会大数据专家 委员会首届委员。其研究连续获得美国国家科学基金委,美国能源部,美国国家卫生局,美国能源研究科学计算中心,美国微软公司,美国斯隆凯特琳癌症中心,美 国巴恩犹太医疗基金,中国科技部973计划资助。曾获KDD(2014),AAAI(2010),ICTAI(2005),ICMLC(2004)等国际 会议的最佳论文奖,和ICDM(2013),RTAS(2012),KDD(2009),ITA(2004)等国际会议的最佳论文奖提名。其开创性的研究 工作获得了美国微软青年教授奖(2007),美国能源科学计算中心启动项目分配奖(2007),和美国能源部杰出青年教授奖(2006)。
以下为分享实景全文:
陈一昕:
感谢新河副秘书长的介绍。首先感谢盟主和联盟为我们提供这么好的一个交流共享的平台,也感谢各位盟友的关注。我一直学习着各位的精彩分享,受益良多。我 也想把自己的一些体会都分享给大家。我想分享的方面比较多,从底层架构,到中间的数据挖掘算法,到上层的大数据对内应用以及匿名化对外开放,但是今天我想 轻松一点,聊一聊算法这块。以后有机会再和大家汇报别的。
我是学计算机的,主要搞算法。大数据对算法和计算理论产生的影响将是非常深刻的。我们很可能正在见证是计算机发展史上的一个重要拐点。可能我们现在还看不太清楚,但是如果我们来看看艺术史,以史为鉴也许会找到一些线索。

让我们从一副画开始。我们小时候都画过画,大部分人都会利用颜色去描绘眼前见到的事物,天空是蓝色,太阳是金色,草地是绿色,等等,就成了一幅画。画家 也是这样,画画的第一任务就是要“像”。早期画家们都是在室内作画,经过一代代长期的积累,画家在把东西画到“像”这件事情上已经达到了无以伦比的极致, 形成了固定的构图和色彩模式。
但是,一个红色的东西经过光的折射在你的眼睛中一定是红色吗?阴影就一定是灰暗色的吗?不一定。光线,质地,空气,温度,甚至心情都可能对颜色的感知(perception)产生影响。

一栋红色的大教堂在秋日黄昏,不同的局部可能展现出千万种不同的颜色。画家们想把更多的信息呈现在眼前的画布上。印象派就是一次重大的突破,画家们走出 画室,回归自然,肩负起了重新研究光与色彩之间关系的历史任务。根据当代科学的发展,了解光的构成,光和色的关系,依靠自己眼睛的观察去再现对象的光和色 在视觉中造成的印象。这样,人们在把握色彩方面完成了一次伟大的革命,诞生了以条件色、对比色、色彩三要素为基石的色彩理论。

你看毕萨罗的大街,莫奈的睡莲,梵高的星空,虽然和照片相比谈不上真实,难道不比照片更接近我们真实的感知(perception)吗?我们甚至能够感 觉到湿冷的空气,人群的流动。印象派通过充分调动每一个象素,用每一个象素来反映颜色、光源、物体、气氛、主题之间的关系,形成了非常生动的整体效果,直 指人心。艺术家们在历史的沉淀中,用画笔在二维空间里表达着事物,文化,思考,感知。
让我们回到数据时代。
历史上人类对数据的探索也在不断的发展,在数字化的当今时代,似乎一切都可以用数据表示。通过将数据抽象成可用的形式,提取出有用的规则和模型,数据科 学家们致力于反映数据中体现出来的知识,事物的本质。他们有着和艺术家们相同的追求,他们用数据表达,感知,探索世界。这和艺术家们对世界的探索进程有着 惊人的相似,二者都反映着从表象到抽象,从描绘勾勒事物到感知事物本质的变化,一如从古典画派到印象画派,从小数据时代到大数据时代。
小数据时代的探究方法就像是古典画派,人们寻求一般性的固定模式,如规定好的构图,相似的饱满色彩,人们追求对事物表象的描述和勾勒,用代代相传的固定 画法展现信仰中的神灵。大数据时代,数据科学家们正犹如印象画派艺术家们对光和色的探索一样,试图用数据反应最真实的本质,寻求充分利用每一个数据的价值 达到深刻的总体结论。
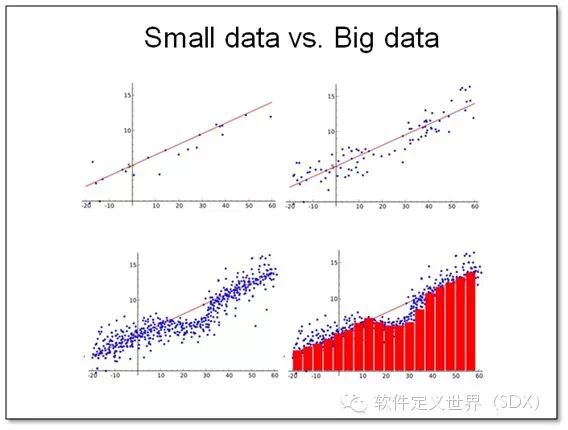
让我们看一个简单例子。当我们建模的时候如果数据量很小,常通过线性回归来逼近给定数据集的分布,如上图中的那条红线。这种方法其实就相当于古典派,也 就是对数据的规则进行了简单的归纳。数据量小的时候,这种归纳有着不错的效果。但是当数据量增大的时候,它并不能完美的展现出数据的关联关系,如左下图表 示的,很明显,中间部分的数据分布红色直线就不能很好地近似表达。那么如果我们用其他的方法(如直方图)就可以对数据分布有更精确的描述。

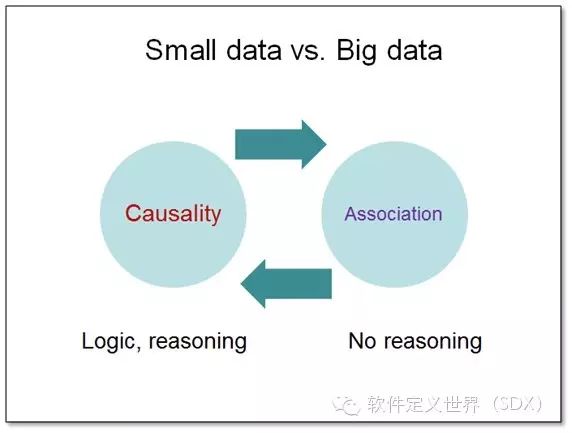
从这个简单的例子中,我们可以看到小数据和大数据的一些对比。小数据模型是一种一般性的规律总结(generalrules),大数据模型则可以发现一 些特殊性的规律(specialdiscovery)。同时,小数据基于逻辑(logic)和推理(reasoning)并且更关心因果性 (causality),而大数据则更关心关联性(association)。这和艺术上是一样的,古典派有固定的规则和理论,而印象派和后续的现代画派 的创作则更多地来自于直观的感受。
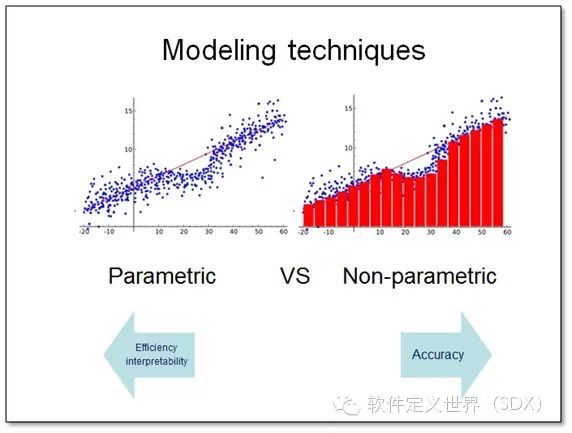
关于大数据和小数据模型技术上的区别来看,可以对应为两类。左边的这一类小数据技术是基于带参模型(parametric)。右面的这一类大数据技术是 基于无参模型(non-parametric)。简单来讲,带参模型有着既定的规则更多的注重技巧,而无参模型则没有提前固化的形式,从而更注重本质。往 往无参模型的准确率更高,就像印象画派一样,展现出来的创作更接近人们真实的感受,它能表达包含更多的信息在画布之中。
当然两类方法各有千秋,在实际工程中还要结合灵活使用。
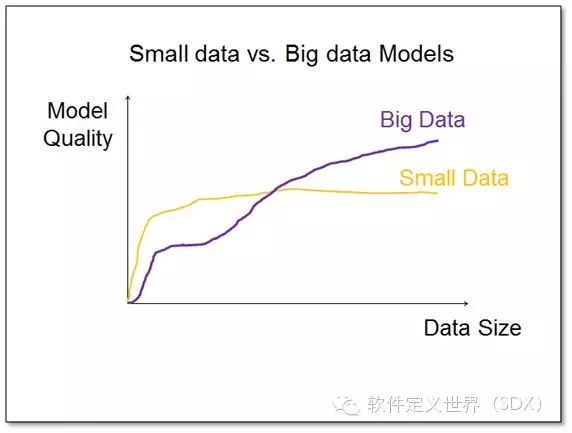
另外一个非常重要的大数据模型和小数据模型的区别,便是大数据模型可以充分利用所有数据的价值。例如下面所示,横坐标为数据集的大小,纵坐标为模型质 量。我们可以看到,当数据集比较小的时候,小数据模型的质量是优于大数据模型的。就像前面提到的线性回归模型(一种带参模型),只有两个点便可以确定一条 直线,如果有10个点那么这个模型可能已经相当准确。
但随着数据量的增加,线性模型却几乎不变。对于直方图(一 种无参模型)来说,如果只有10个点的话,结果则显得非常不准确,但是随着数据量的增长,这种方法却会越来越准确。总结来讲,随着数据量的增加,小数据的 模型质量会接近饱和甚至降低,因为有过拟合的问题。而大数据模型则会随着数据量的增长,模型质量不断提升。
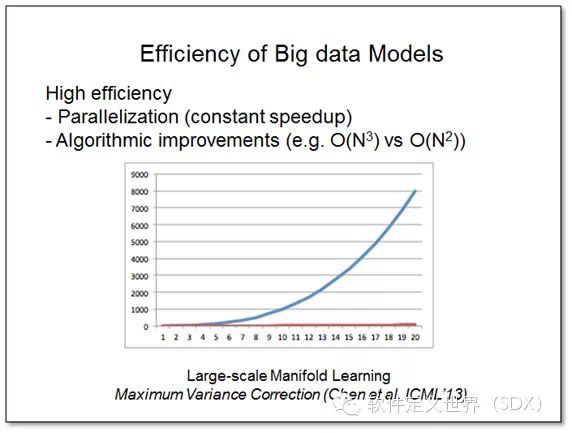
那么提到分析大数据的手段,人人往往会提及Hadoop,搭集群配节点,用并行计算框架来解决大数据问题。但人们早已经意识到大数据不仅仅是 Hadoop(BigData≠Hadoop)。因为并行计算框架在解决大数据问题上,存在两个问题:一,性能依赖硬件且有限,比如增加了100个节点, 那么理想情况下速度提升了100倍,但这种速度的提升为常数增长;二,很多任务缺乏并行性,无法高效并行完成。
并行计算框架真正运行任务的时候其实很难达到我们预期中速度增长与硬件升级的匹配。所以,我们在看到并行计算能力的同时,改进解决大数据问题的算法是更为重要的手段。
上面这张图展示的,是我们在2013年国际机器学习大会(ICML-13)会议上关于大规模流形学习算法的结果展示。我们把时间复杂度从O(N^3) (蓝线)降低到了O(N^2)(红线),并且随着数据量的增加,这种指数级的速度递减会越快。由此可见,算法的力量比硬件的升级带来的效果更强大。所以在 未来大数据的研究应当不仅仅关注搭建并行化的平台,更要关注平台上算法的研究。
关于算法的力量有很多例子。最近网上有一篇连载的文章《硅谷的那些事》中,提到了网景公司当年的成功就是因为算法改进导致浏览器的性能大大超出了原来NCSA的Mosaic浏览器。量变引起了质变。
当然艺术和大数据还是有差异的。艺术家在二维的空间里作画,画得再印象派,想要表达的内容再多,也就是维度再高,工作量也是有限的。但是数据却是在高维空间里的,想要充分描述的空间规模是指数级增长的。计算量可以大到不切实际而且数据点很稀疏无法建模。
这个问题怎么解决呢?套路还是有不少的。
我们研究过两种。一个就是采取混合式(hybrid)建模,例如可以带参数(parametric)模型加上无参(non-parametric)模 型,判别(discriminative)模型结合生成((generative)模型,非线性(nonlinear)模型加上线性(linear)模 型。就好比先对一些低维空间分开用印象派描述,再用经典画派的手法把他们综合起来。这样可以一定程度上解决稀疏性以及计算量的问题。
还有一个就是降维和流形学习,就是把高维的数据先嵌套在一个合理的低维度空间里再建模。这也好比毕加索的画一样,把同一个事物的多个角度整合在一个二维平面上。
我们先来看混合模型的方法,以分类这个机器学习中的基本问题做例子,来看大数据时代对分类器的要求及我们混参模型的特性。分类是一个数据挖掘的核心任 务,有着广泛的应用,比如基于运营商大数据的用户流失分析,垃圾短信治理,特定用户识别,信贷评级,精准广告营销,以及医疗大数据中的突发事件预警,疾病 监控等等。
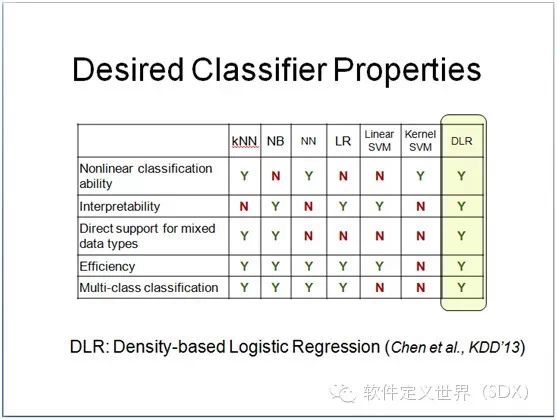
列表中我们看到,对分类模型而言,首先重要的是非线性的分析能力,因为很多数据的分类界限是非常复杂的,需要有非线性的分析能力才能达到很好的效果。第 二是可解释性,模型的结果应当有意义,且利于分析人员进行操作。比如,基于核函数的支持向量机虽然效果很好但是却不具备可解释性。第三是希望分类器能够支 持混合的数据类型。第四,由于在大数据时代数据量十分庞大,所以需要模型具有高效性。第五,需要模型具有稀疏性,建模往往包含了很多的指标,这里的稀疏性 指希望模型可以自动的选出较少的有效指标,而不是包含所有的指标。
那么从这张图中我们可以看到大部分现有模型都 不能同时满足这五点要求。我们在KDD-2013年的会议上提出了一种新的模型,即基于核密度的逻辑回归(Density- basedLogisticRegression,缩写为DLR)。它的基本思想是将数据的每一个维度先通过核密度估计这样一个无参模型进行处理,然后再 利用带参的逻辑回归模型把所有维度整合在一起。这样的模型取得了良好的效果,可以同时满足上述的五个要求。
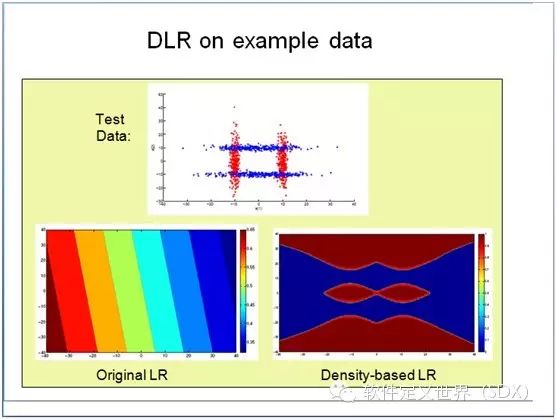
上面这张图展示了基于核密度的逻辑回归模型与传统逻辑回归的效果上的差别。我们可以看到给定数据集中红色点和蓝色点交叉在一起形成了一个井字。我们的任 务就是训练一个分类器将两类数据分开来。左下的图展现了传统逻辑回归得出的结果,我们看到无论怎样用直线分类,也就是训练线性分类器注定是失败的。右下的 图则是我们基于密度的逻辑回归模型,我们可以很清楚的看到蓝色和红色点的界限。
可以看到,传统的逻辑回归就像古 典画派一样用固定的parametric模式来分析数据。但是我们引入了印象派的non-parametric的核密度估计来处理特征,让逻辑回归模型建 立在所有数据的真实分布上。就好像原来作画是定下形状填颜色,而我们并不先定义形状,而是通过层层描绘每一个象素,来反映真实感知到的颜色,而让这些象素 最终形成更贴近真实的大数据分布效果图。可以看到原来的逻辑回归是线性分类,不能将红点和蓝点很好区分开,而我们的新模型可以。
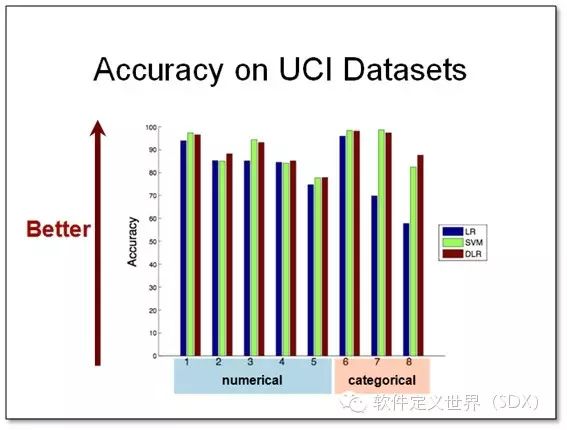
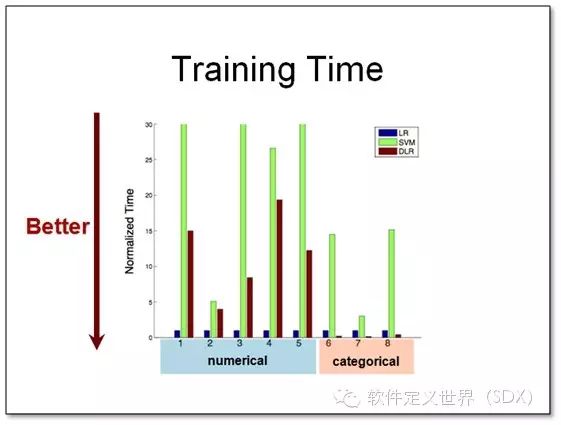
这两张图展示了我们的模型可以达到和非线性支持向量机(SVM)相近的准确度,而时间复杂度则是和线性模型接近的。
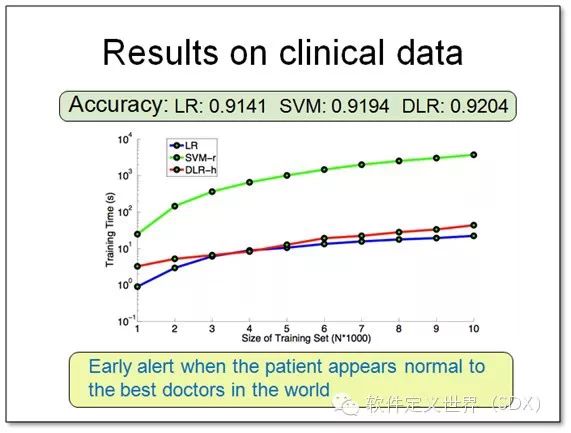
这张图展示的是我们将该模型(DLR)应用在美国华盛顿大学医院医疗大数据的例子。在这里我们使用了病人的 EHR(ElectronicHealthRecord)作为数据集,来预测突发疾病。我们的模型达到了非常好的预测效果,效率非常高,同时模型具有可解 释性,可以指出病人的发病原因方便护士和医生进行干预治疗。该项目已经在美国著名医院进行了临床试验。
在2014年,我们对该模型进行了进一步完善,并发表在KDD2014会议上,获得了最佳学生论文奖亚军。原来的模型是针对每一个维度单独进行处理,假 设条件是维度之间相互独立。而在2014年的模型中,我们可以将多个维度整合成一个子空间进行密度预测,并用次模优化 (submodularoptimization)的方法来自动选择稀疏的子空间,进一步增强了效果。


我想上述的两种算法在某种程度上其实反映了大数据算法的精髓,也就是把无参模型和带参模型的相结合来同时满足效率和准确度的要求,同时也将关联性和因果 性进行了结合。也就是我所提出的观点,对于真正的大数据我们可能需要摆脱过于复杂的模型(heavymachinery),而在简单的模型中引入一定的非 线性来达到比较好的效果,充分发挥数据价值。
在小数据时代,样本也就是数据在比较少的情况下是非常珍贵的,所以 往往模型会做的比较复杂。比如像在贝叶斯流派的算法中需要对每一个点的意义进行深层次的挖掘。但是在大数据时代,当我们有成千上亿的数据点,有一些误差和 噪音是没有关系的,一些简单的模型反而执行效率更高,并且模型质量会随着数据量的增长而增加。所以说大数据时代,我们应当充分发挥数据的价值,而模型可以 简单一些。
那么我们看看第二个方向。对计算量可以大到不切实际而且数据点很稀疏无法建模的这个问题,另一个思路就是对数据进行降维,在此我们对主流的流形学习进行了研究和优化。
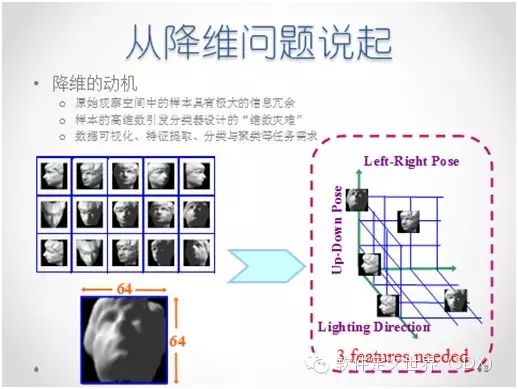
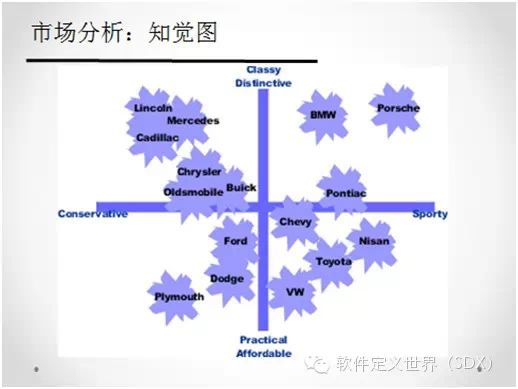
如图中所示,虽然每一张图片的维度都很高(64x64),但其实只有三个维度的变化。再比如这张图显示的,汽车有很多的属性,我们可以通过降维自动的把这些属性映射到二维空间内,而空间里的距离同时又很好的反映了物体之间的相似度。
在处理大数据的时候,维度太高会引起维度灾难。计算量非常大而且数据很稀疏不易处理,降维往往是一个很关键的必要步骤。但是现在做大数据分析工作时有些 分析人员往往完全忽略了降维。比如电信运营商的数据源很丰富,数据维度很高(用户基本信息,通话,短信,上网,位置,等等)。直接将一些通用性的算法作用 在高维度的数据上,这样做其实很多时候是没有太多意义的。
而且不同的值的度量尺度也不同。比如年龄,通话时长,上网流量等等都在不同的尺度空间里,如果直接套用一些算法是完全错误的。所以必须降维把这些数据整合到同一个尺度空间中,再用其他模型进行分析。降维算法也和推荐系统,精准营销有着深刻的联系。
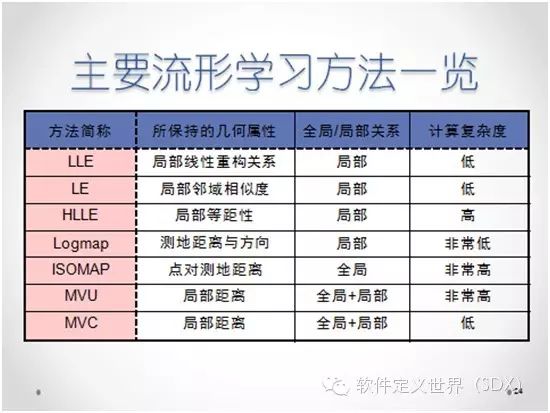
这张图总结了主流的流形学习算法。
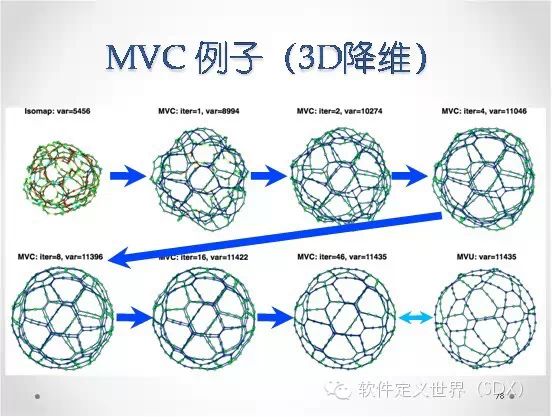
我们在这方面做了研究,把目前主流的一个算法最大方差展开(MVU)进行了优化,形成了新的算法最大方差更新(MVC)。把时间复杂度从O(N3)降低到O(N2),并且可以并行分布式实现,从高大大提高了对大规模数据高效率的降维操作能力。
W.Chen,Y.Chen,K.Weinberger,Q.Lu,andX.Chen,Goal-OrientedEuclideanHeuristicswithManifoldLearning, Proc.AAAIConferenceonArtificialIntelligence(AAAI-13), 2013.(PDF)
W.Chen,K.Weinberger,andY.Chen,MaximumVarianceCorrectionwithApplicationtoA*Search,Proc.InternationalConferenceonMachineLearning(ICML-13),2013.
主要是这两篇论文
以上就两个方向的探索的简介。
大数据分析既是科学又是艺术。随着大数据时代的进程,那下一步是不是应该继续从艺术史中获取灵感呢?

可以考虑现代派抽象主义里的代表人物毕加索的立体抽象派和蒙德里安的几何抽象派。他们的创作早已脱离了对物纯粹的描绘,摒弃了对物的依附,更多地是抽象甚至更为简洁的感知表达,反映人内心的真实感受而无需拘泥于“像”。
又比如说,既然音乐可以不附着于任何具体物体形状而通过音符的组合表达感情,为什么绘画不能通过色素的组合来表达本质,直指人心呢?
那么对大数据分析来讲也是这样的。无论数据多么复杂,对于决策者和行动者来说往往事情是非常简单的:做或者不做。大数据模型最终想表达的本质其实也是个 很简单的东西,这就启发我们大数据工作者在制定模型和处理数据的时候最终追求的应该是更加的简洁,更加直指本质的一种形式。
正所谓大道至简,大道同归,我想也正如科学和艺术的发展史一样,在大数据时代,有更多的本质和美值得我们探索发现。
这里鸣谢一下,流形学习的部分材料来自:
1.王瑞平,中国科学院计算技术研究所
2.AlexeiEfros,卡内基梅隆大学
我今天的分享就到这里。谢谢各位老师朋友,欢迎提问指正。
交流互动
皇上:
如痴如醉,这才应该是周六学术论坛的演讲内容啊!
沈备军:
有什么相关的中文书籍推荐吗?
陈一昕:
《数学之美》;作者吴军大家都很熟悉。这本书主要的作用是引起了我对机器学习和自然语言处理的兴趣。里面以极为通俗的语言讲述了数学在这两个领域的应 用。《统计学习方法》;作者李航,是国内机器学习领域的几个大家之一,曾在MSRA任高级研究员,现在华为诺亚方舟实验室。书中写了十个算法,每个算法的 介绍都很干脆,直接上公式,是彻头彻尾的“干货书”。每章末尾的参考文献也方便了想深入理解算法的童鞋直接查到经典论文;本书可以与上面两本书互为辅助阅 读。《MachineLearning》(《机器学习》);作者TomMitchell是CMU的大师,有机器学习和半监督学习的网络课程视频。这本书是 领域内翻译的较好的书籍,讲述的算法也比《统计学习方法》的范围要大很多。据评论这本书主要在于启发,讲述公式为什么成立而不是推导;不足的地方在于出版 年限较早,时效性不如PRML。但有些基础的经典还是不会过时的,所以这本书现在几乎是机器学习的必读书目。
《DataMining:PracticalMachineLearningToolsandTechniques》(《数据挖掘:实用机器学习技 术》);作者IanH.Witten、EibeFrank是weka的作者、新西兰怀卡托大学教授。他们的《ManagingGigabytes》[4] 也是信息检索方面的经典书籍。这本书最大的特点是对weka的使用进行了介绍,但是其理论部分太单薄,作为入门书籍还可。
《PatternRecognitionAndMachineLearning》;作者ChristopherM.Bishop[6];简称PRML, 侧重于概率模型,是贝叶斯方法的扛鼎之作,据评“具有强烈的工程气息,可以配合stanford大学AndrewNg教授的 MachineLearning视频教程一起来学,效果翻倍。”
《TheElementsofStatisticalLearning:DataMining,Inference,andPrediction》, (《统计学习基础:数据挖掘、推理与预测》第二版);作者RobertTibshirani、TrevorHastie、JeromeFriedman。 “这本书的作者是Boosting方法最活跃的几个研究人员,发明的GradientBoosting提出了理解Boosting方法的新角度,极大扩展 了Boosting方法的应用范围。这本书对当前最为流行的方法有比较全面深入的介绍,对工程人员参考价值也许要更大一点。另一方面,它不仅总结了已经成 熟了的一些技术,而且对尚在发展中的一些议题也有简明扼要的论述。让读者充分体会到机器学习是一个仍然非常活跃的研究领域,应该会让学术研究人员也有常读 常新的感受。”
《DataMining:ConceptsandTechniques》,(《数据挖掘:概念与 技术》第三版);作者(美)JiaweiHan、(加)MichelineKamber、(加)JianPei,其中第一作者是华裔。本书毫无疑问是数据 挖掘方面的的经典之作,不过翻译版总是被喷,没办法,大部分翻译过来的书籍都被喷,想要不吃别人嚼过的东西,就好好学习英文吧。 D.Hand,H.MannilaandP.Smith,PrincipleofDataMining.
本书从统计学的角度看待数据挖掘,因为统计学是一门数学,所以本书强调数学上的正确性(Validity)。按照本书观点,数据挖掘是分析(往往是大量的)数据集以找到未曾预料的关系,并以可理解又有用的新颖方式呈现给数据用户的过程。
Pang-NingTan,VipinKumaretc.IntroductiontoDataMining
(http://book.douban.com/subject/1465939/)。
国内目前有翻译版(http://book.douban.com/subject/1786120/),这是我现在觉得最好的数据挖掘教材。关于分 类、关联规则、聚类每一主题都分两章来讲述:第一章讲基本部分,第二章讲高级部分,让人由浅入深。另有单独的一章介绍异常检测。本书的第一作者是物理背景 出身,所以讲解很重视对于算法的理解(优缺点与适用范围等)。本书能找到PDF版完整的习题答案,非常适合于自学。
《MiningofMassiveDatasets》(《大数据》);作者AnandRajaraman[3]、 JeffreyDavidUllman,Anand是Stanford的PhD。这本书介绍了很多算法,也介绍了这些算法在数据规模比较大的时候的变形。 但是限于篇幅,每种算法都没有展开讲的感觉,如果想深入了解需要查其他的资料,不过这样的话对算法进行了解也足够了。还有一点不足的地方就是本书原文和翻 译都有许多错误,勘误表比较长,读者要用心了。
这些都是我网上找来的,不是原创。以前给我的团队总结的。
还是推荐一下韩家炜老师的书,《数据挖掘:概念与技术》第三版,非常经典。
韩老师也是我在UIUC时的老师,虽然不是博士论文导师,但是和韩老师学到好多。
沈醉:
bravo!
沈醉:
正在kdd的keynote现场,陈老师这里更精彩
陈一昕:
谢谢。我学生去了。就是两篇论文的作者。陈稳霖
黄劲:
马上下单,贡布里希。
whfCarter:
混合式学习目前感觉成为dm的标配,各种公司在广告点击预测等应用也有使用,谢谢陈教授分享干货。
陈一昕:
谢谢,希望向您多了解各种混合模型
BrightStar:
真的很感谢联盟,陈教授平时很少有时间给我们将这些。
陈一昕:
我以后多交流,再次感谢各位盟友捧场。希望以后向大家多多交流、学习
陈一昕:
感谢联盟的组织者辛苦工作。
阮彤:
医疗大数据应用那块,我们在国内数据挖掘,不知有无可能和美国的数据比对?主要是预测哪一类疾病的?
陈一昕:
我们在美国主要是根据病人的生命体征的多维时间序列数据,预测突发疾病(败血病,心肌梗塞,呼吸道感染)风险,还有慢性病人的风险系数,目前尚没有和国内医疗数据挖掘的直接对比。
夏明武:
艺术类做大数据,看来算法非常重要
陈一昕:
是的,大数据处理可以大致分为数据预处理平台,整合数据仓库,和深度探索平台。算法对深度探索平台尤为重要。像teradataaster这样的深度分析平台就在算法上有优势。一些复杂分析算法是不适合在其他两类平台上实现的。
whfCarter:
不同的平台用于不同的场景
陈一昕:
陈一昕:
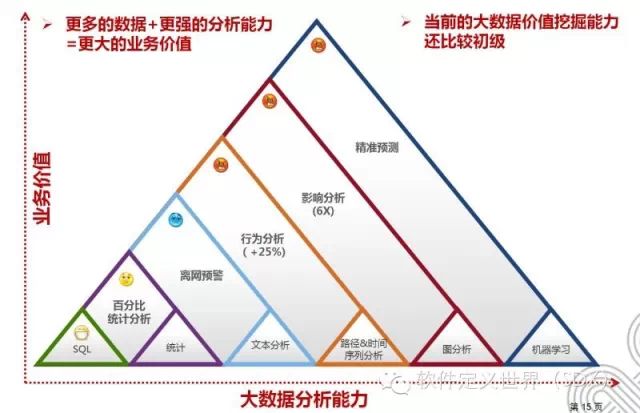
更多的数据+更强的分析能力=更大的业务价值
陈一昕:
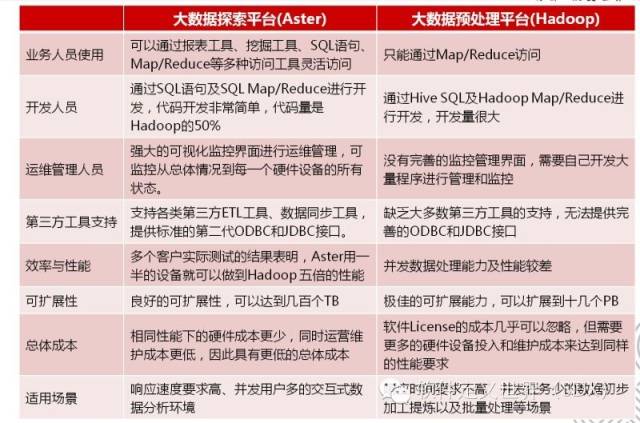
当前不少机构的大数据价值挖掘能力还比较初级,这也是很好的机会。
DowsonLiu(刘睿民):
韩家炜老师的书《数据挖掘:概念与技术》最近有看了,太经典。国内其实很多好的老师,写的东西非常有料
陈一昕:
当然各有其用,混搭式平台,UDA架构看来比较靠谱。
夏明武:
象我以前做电信行业,算法相对简单很多
陈一昕:
是的
夏明武:
在去哪儿时,以结果为导向,更是不怎么用算法,快速、高效做出结果就OK了
DowsonLiu(刘睿民):
陈教授对传统的算法在大数据下的应用不知道有什么心得?感觉现在象MR这样的架构是有用,但是从数学的角度来说,不美!
DowsonLiu(刘睿民):
mapreduce有点简单暴力
陈一昕:
mapreduce挺美的,但是对编程人员来说,要求比较高,开发复杂算法有点累。而且性能可能一下子并不太好,需要反复优化。还有大量算法可能无法放进标准的MR框架内
......
罗啸:
提一点建议一个想法:可以用本土的工笔和水墨历史来讲啊,似乎更亲切。[呲牙]想法:希望数据挖掘界也能出类似于《大话移动通信》类的书籍,用生活中例子深入浅出的讲解技术。
DowsonLiu(刘睿民):
对呀,这是非常纠结的事
陈一昕:
我只是跟着学艺术史的老婆学了一点点皮毛
罗啸:
触类旁通,能以史为镜,以史为鉴,佩服!
DowsonLiu(刘睿民):
这个比喻贴切!一个细腻,一个大刀阔斧子!
DowsonLiu(刘睿民):
陈教授的分享太精彩了!而且落地医疗绝对的有现实意义。
陈一昕:
谢谢各位,欢迎各位联系。以后有机会再分享一些实战案例。晚安。
陈新河:中关村大数据产业联盟副秘书长;《软件定义世界,数据驱动未来》,非常感谢一昕的精彩分享!
点击最上面蓝色微信名关注我们
微信公众号:O2OArt
北京朝阳朝阳路红星美凯龙温钦画廊
OrderArtwork.com,13811793577
温钦画廊,O2O现代画廊,实体店+艺术品电商+掌上画院,照片定制纯手绘油画全球领头羊,多年来向全球提供高品质的各种风格的原创、定制和临摹纯手绘油画、国画、书画作品、墙绘和艺术摆件;
扫一扫温钦画廊微信公众号:O2OArt





